
WatchAct: A Benchmark for Behavior-Grounded Robot Manipulation
Baiqi Li, Ce Zhang, Yu Fang, Yue Yang, Shangzhe Li, Mingyu Ding, Gedas Bertasius
arXiv 2026
[arxiv] [project page] [code] [data] [bibtex]

SVI-Bench: A Dynamic Microworld for Strategic Video Intelligence
Yulu Pan, Han Yi, Seongsu Ha, Md Mohaiminul Islam, Benjamin Zhang, Lorenzo Torresani, Gedas Bertasius
ECCV 2026
[arxiv] [video] [project page] [extended paper] [code] [data] [bibtex]

LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
Yue Yang, Shuo Cheng, Yu Fang, Homanga Bharadhwaj, Mingyu Ding,
Gedas Bertasius, Daniel Szafir
arXiv 2026
[arxiv] [project page] [video] [code] [bibtex]

TimeBlind: A Spatio-Temporal Compositionality Benchmark for Video LLMs
Baiqi Li, Kangyi Zhao, Ce Zhang, Chancharik Mitra, Jean de Dieu Nyandwi,
arXiv 2026
[arxiv] [project page] [code] [dataset] [bibtex]

V2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation
Yan-Bo Lin, Jonah Casebeer, Long Mai, Aniruddha Mahapatra,
Gedas Bertasius, Nicholas J. Bryan
arXiv 2026
[arxiv] [project page] [bibtex]

TeDiO: Temporal Diagonal Optimization for Training-Free Coherent Video Diffusion
Nurislam Tursynbek, Zhiqiang Lao, Heather Yu, Gedas Bertasius, Marc Niethammer
CVPR 2026 Workshop on Agentic AI for Visual Media
[arxiv] [bibtex]

DocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Tanveer Hannan, Dimitrios Mallios, Parth Pathak, Faegheh Sardari, Thomas Seidl, Gedas Bertasius, Mohsen Fayyaz, Sunando Sengupta
CVPR 2026 Findings
[arxiv] [code] [bibtex]

SiLVR: A Simple Language-based Video Reasoning Framework
Ce Zhang, Yan-Bo Lin, Ziyang Wang, Mohit Bansal, Gedas Bertasius
TMLR 2026 (1st Place Winner at CVPR 2025 MMLU Challenge)
[arxiv] [project page] [code] [bibtex]

Zero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising
Yan-Bo Lin, Kevin Lin, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Chung-Ching Lin, Xiaofei Wang, Gedas Bertasius, Lijuan Wang
WACV 2026 (Oral)
[arxiv] [project page] [code] [bibtex]

TimeRefine: Temporal Grounding with Time Refining Video LLM
Xizi Wang, Feng Cheng, Ziyang Wang, Huiyu Wang, Md Mohaiminul Islam, Lorenzo Torresani, Mohit Bansal, Gedas Bertasius, David Crandall
WACV 2026

Enhancing Visual Planning with Auxiliary Tasks and Multi-token Prediction
Ce Zhang, Yale Song, Ruta Desai, Michael Louis Iuzzolino, Joseph Tighe, Gedas Bertasius, Satwik Kottur
WACV 2026
[arxiv] [bibtex]

ReAgent-V: A Reward-Driven Multi-Agent Framework for Video Understanding
Yiyang Zhou, Yangfan He, Yaofeng Su, Siwei Han, Joel Jang, Gedas Bertasius, Mohit Bansal, Huaxiu Yao
NeurIPS 2025
[arxiv] [bibtex]

ExAct: A Video-Language Benchmark for Expert Action Analysis
Han Yi, Yulu Pan, Feihong He, Xinyu Liu, Benjamin Zhang, Oluwatumininu Oguntola, Gedas Bertasius
NeurIPS Datasets and Benchmarks Track 2025
[arxiv] [project page] [code] [dataset] [leaderboard] [bibtex]

Ziyang Wang, Jaehong Yoon, Shoubin Yu, Md Mohaiminul Islam, Gedas Bertasius, Mohit Bansal
EMNLP 2025
[arxiv] [project page] [code] [bibtex]

BOSS: Benchmark for Observation Space Shift in Long-Horizon Task
Yue Yang, Linfeng Zhao, Mingyu Ding, Gedas Bertasius, Daniel Szafir
Robotics and Automation Letters (RA-L) 2025

ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis
Yu Fang, Yue Yang, Xinghao Zhu, Kaiyuan Zheng, Gedas Bertasius, Daniel Szafir, Mingyu Ding
IROS 2025
[arxiv] [project page] [code] [bibtex]
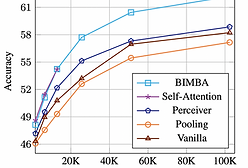
BIMBA: Selective-Scan Compression for Long-Range Video Question Answering
Md Mohaiminul Islam, Tushar Nagarajan, Huiyu Wang, Gedas Bertasius, Lorenzo Torresani
CVPR 2025 (1st Place Winner at CVPR 2025 Ego4D EgoSchema Challenge)
[arxiv] [project page] [code] [model] [demo] [bibtex]

BASKET: A Large-Scale Video Dataset for Fine-Grained Skill Estimation
Yulu Pan, Ce Zhang, Gedas Bertasius
CVPR 2025
[arxiv] [project page] [code] [data] [bibtex]

VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long Videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, Mohit Bansal
CVPR 2025
[arxiv] [project page] [code] [bibtex]

ReVisionLLM: Recursive Vision-Language Model for Temporal Grounding in Hour-Long Videos
Tanveer Hannan, Md Mohaiminul Islam, Jindong Gu, Thomas Seidl, Gedas Bertasius
CVPR 2025

VMAs: Video-to-Music Generation via Semantic Alignment in Web Music Videos
Yan-Bo Lin, Yu Tian, Linjie Yang, Gedas Bertasius, Heng Wang
WACV 2025 (Oral)
[arxiv] [project page] [code] [bibtex]

DAM: Dynamic Adapter Merging for Continual Video QA Learning
Feng Cheng, Ziyang Wang, Yi-Lin Sung, Yan-Bo Lin, Mohit Bansal, Gedas Bertasius
WACV 2025

A Simple LLM Framework for Long-Range Video Question-Answering
Ce Zhang*, Taixi Lu*, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, Gedas Bertasius
EMNLP 2024

Augmented Reality Demonstrations for Scalable Robot Imitation Learning
Yue Yang, Bryce Ikeda, Gedas Bertasius, Daniel Szafir
IROS 2024

Xiyao Wang, Yuhang Zhou, Xiaoyu Liu, Hongjin Lu, Yuancheng Xu, Feihong He, Jaehong Yoon, Taixi Lu, Gedas Bertasius, Mohit Bansal, Huaxiu Yao, Furong Huang
ACL 2024

Propose, Assess, Search: Harnessing LLMs for Goal-Oriented Planning in Instructional Videos
Md Mohaiminul Islam, Tushar Nagarajan, Huiyu Wang, Fu-Jen Chu, Kris Kitani, Gedas Bertasius, Xitong Yang
ECCV 2024 (Oral)
[arxiv] [project page] [bibtex]

Siamese Vision Transformers are Scalable Audio-visual Learners
Yan-Bo Lin, Gedas Bertasius
ECCV 2024


4Diff: 3D-Aware Diffusion Model for Third-to-First Viewpoint Translation
Feng Cheng*, Mi Luo*, Huiyu Wang, Alex Dimakis, Lorenzo Torresani, Gedas Bertasius, Kristen Grauman
ECCV 2024
[arxiv] [bibtex]

RGNet: A Unified Clip Retrieval and Grounding Network for Long Videos
Tanveer Hannan, Md Mohaiminul Islam, Thomas Seidl, Gedas Bertasius
ECCV 2024

Video ReCap: Recursive Captioning of Hour-Long Videos
Md Mohaiminul Islam, Ngan Ho, Xitong Yang, Tushar Nagarajan, Lorenzo Torresani, Gedas Bertasius
CVPR 2024 (Egocentric Vision Distinguished Paper Award)
[arxiv] [project website] [code] [dataset] [bibtex]

Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Gedas Bertasius, ... , Michael Wray
CVPR 2024 (Oral)
[arxiv] [project website] [blog] [video] [bibtex]

LoCoNet: Long-Short Context Network for Active Speaker Detection
Xizi Wang, Feng Cheng, Gedas Bertasius, David Crandall
CVPR 2024

Unified Coarse-to-Fine Alignment for Video-Text Retrieval
Ziyang Wang, Yi-Lin Sung, Feng Cheng, Gedas Bertasius, Mohit Bansal
ICCV 2023

SimpleClick: Interactive Image Segmentation with Simple Vision Transformers
Qin Liu, Zhenlin Xu, Gedas Bertasius, Marc Niethammer
ICCV 2023

VindLU: A Recipe for Effective Video-and-Language Pretraining
Feng Cheng, Xizi Wang, Jie Lei, David Crandall, Mohit Bansal, Gedas Bertasius
CVPR 2023

Vision Transformers are Parameter-Efficient Audio-Visual Learners
Yan-Bo Lin, Yi-Lin Sung, Jie Lei, Mohit Bansal, Gedas Bertasius
CVPR 2023
[arxiv] [code] [project page] [bibtex]

Efficient Movie Scene Detection using State-Space Transformers
Md Mohaiminul Islam, Mahmudul Hasan, Kishan Athrey, Tony Braskich, Gedas Bertasius
CVPR 2023

Improving Video Retrieval Using Multilingual Knowledge Transfer
Avinash Madasu, Estelle Aflalo, Gabriela Ben Melech Stan, Shao-Yen Tseng, Gedas Bertasius, Vasudev Lal
ECIR 2023 (Best Student Paper Award)
[arxiv]

Learning to Retrieve Videos by Asking Questions
Avinash Madasu, Junier Oliva, Gedas Bertasius
ACM Multimedia 2022

ECLIPSE: Efficient Long-range Video Retrieval using Sight and Sound
Yan-Bo Lin, Jie Lei, Mohit Bansal, Gedas Bertasius
ECCV 2022 (Oral)
[arxiv] [code] [project page] [bibtex]

TALLFormer: Temporal Action Localization with a Long-memory Transformer
Feng Cheng, Gedas Bertasius
ECCV 2022

Long Movie Clip Classification with State-Space Video Models
Md Mohaiminul Islam, Gedas Bertasius
ECCV 2022

Learning To Recognize Procedural Activities with Distant Supervision
Xudong Lin, Fabio Petroni, Gedas Bertasius, Marcus Rohrbach, Shih-Fu Chang, Lorenzo Torresani
CVPR 2022
[arxiv] [code] [project page] [bibtex]

Long-Short Temporal Contrastive Learning of Video Transformers
Jue Wang, Gedas Bertasius, Du Tran, Lorenzo Torresani
CVPR 2022

Is Space-Time Attention All You Need for Video Understanding?
Gedas Bertasius, Heng Wang, Lorenzo Torresani
ICML 2021 (Top-5 Most Impactful ICML 2021 Paper)
[arxiv] [code] [talk] [slides] [Facebook AI Blog] [VentureBeat] [SiliconAngle] [bibtex]

Vx2Text: End-to-End Learning of Video-Based Text Generation from Multimodal Inputs
Xudong Lin, Gedas Bertasius, Jue Wang, Shih-Fu Chang, Devi Parikh, Lorenzo Torresani
CVPR 2021
[arxiv] [VentureBeat] [bibtex]

Supervoxel Attention Graphs for Long-Range Video Modeling
Yang Wang, Gedas Bertasius, Tae-Hyun Oh, Abhinav Gupta, Minh Hoai, Lorenzo Torresani
WACV 2021

COBE: Contextualized Object Embeddings from Narrated Instructional Video
Gedas Bertasius, Lorenzo Torresani
NeurIPS 2020
[arxiv] [talk] [slides] [HowTo100M_BB pseudo annotations] [bibtex]

Attentive Action and Context Factorization
Yang Wang, Vinh Tran, Gedas Bertasius, Lorenzo Torresani, Minh Hoai
BMVC 2020
[arxiv]

Classifying, Segmenting, and Tracking Objects in Video with Mask Propagation
Gedas Bertasius, Lorenzo Torresani
CVPR 2020 (Best Paper Finalist)
Ranked 1st on YouTube-VIS Leaderboard and EPIC-Kitchens Detection Challenge.
[arxiv] [talk] [slides] [bibtex]

Learning Temporal Pose Estimation from Sparsely-Labeled Videos
Gedas Bertasius, Christoph Feichtenhofer, Du Tran, Jianbo Shi, Lorenzo Torresani
NeurIPS 2019
Ranked 1st on PoseTrack Leaderboard for multi-frame pose estimation.
[arxiv] [poster] [code] [bibtex]

Object Detection in Video with Spatiotemporal Sampling Networks
Gedas Bertasius, Lorenzo Torresani and Jianbo Shi
ECCV 2018
[arxiv] [results] [bibtex]
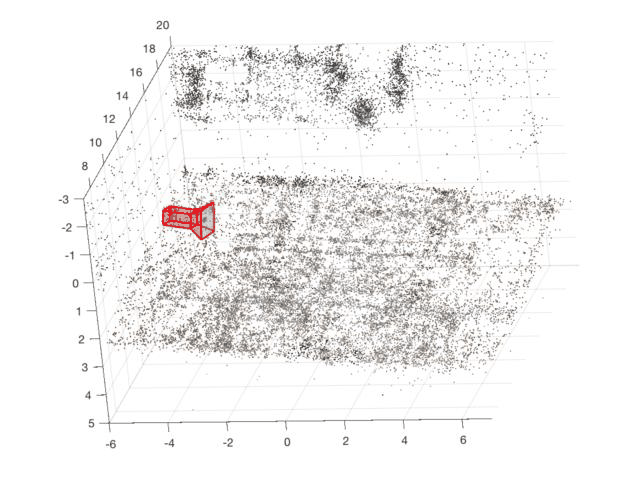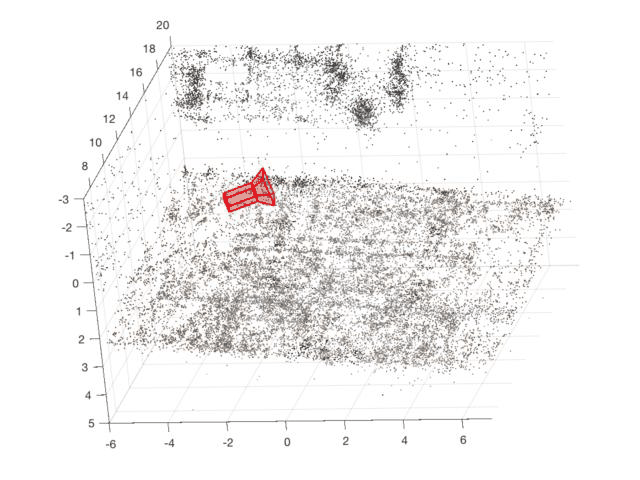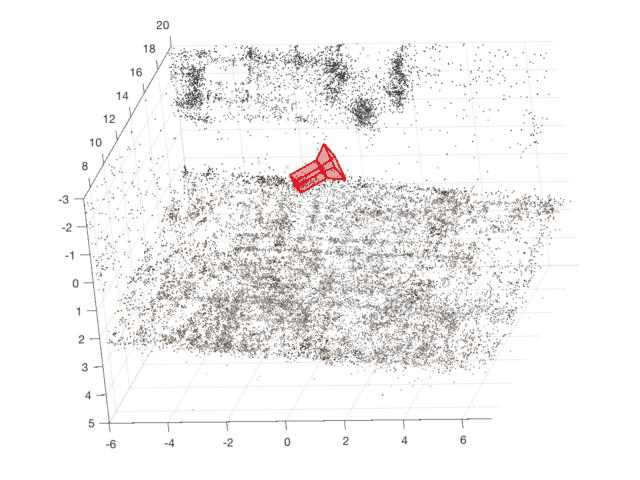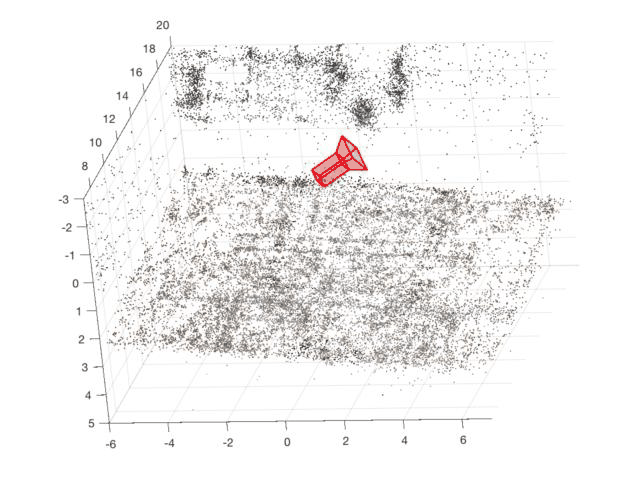
Egocentric Basketball Motion Planning from a Single First-Person Image
Gedas Bertasius, Aaron Chan and Jianbo Shi
CVPR 2018
[arxiv] [results] [MIT SSAC Poster] [bibtex]

Am I a Baller? Basketball Performance Assessment from First-Person Videos
Gedas Bertasius, Stella X. Yu, Hyun Soo Park and Jianbo Shi
ICCV 2017
[arxiv] [results] [bibtex]

Unsupervised Learning of Important Objects from First-Person Videos
Gedas Bertasius, Hyun Soo Park, Stella X. Yu and Jianbo Shi
ICCV 2017
[arxiv] [bibtex]
Convolutional Random Walk Networks for Semantic Image Segmentation
Gedas Bertasius, Lorenzo Torresani, Stella X. Yu and Jianbo Shi
CVPR 2017
[arxiv] [bibtex]

First-Person Action-Object Detection with EgoNet
Gedas Bertasius, Hyun Soo Park, Stella X. Yu, and Jianbo Shi
RSS 2017
[arxiv] [New Scientist Article] [Impact Article] [results] [bibtex]

Local Perturb-and-MAP for Structured Prediction
Gedas Bertasius, Qiang Liu, Lorenzo Torresani, and Jianbo Shi
AISTATS 2017
[arxiv] [bibtex]

Semantic Segmentation with Boundary Neural Fields
Gedas Bertasius, Jianbo Shi and Lorenzo Torresani
CVPR 2016
[arxiv] [code] [bibtex]

High-for-Low, Low-for-High: Efficient Boundary Detection from Deep Object Features and its Applications to High-Level Vision
Gedas Bertasius, Jianbo Shi, and Lorenzo Torresani
ICCV 2015
[arxiv] [code] [bibtex]

DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection
Gedas Bertasius, Jianbo Shi, and Lorenzo Torresani
CVPR 2015
[arxiv] [bibtex]